Diving Deep: What Makes Database Indexing Lightning Fast
Introduction
I’ve always been fascinated by how fast databases are. You can run a query like SELECT * FROM employees WHERE employee_id = 5, and the result is back almost instantly, even if the table has millions of rows. At some point, I stopped and thought: How does the database actually do that? What’s happening under the hood that makes this so efficient?
That question led me down the rabbit hole of indexing and more specifically, to the elegant data structure that makes it all possible: the B-tree.
Indexing, as a concept, wasn’t always part of the database world. In the early days of computing, searching for a record meant scanning every row in a file which means when you’re working with disk storage, was painfully slow. In the 1970s, Rudolf Bayer and colleagues at Boeing realized this problem needed a smarter solution. Their answer? The B-tree - a balanced, disk-friendly structure designed to keep data sorted and searchable with minimal reads.
The Role of B-trees in Modern Databases
Today, B-trees (and their cousin, the B+ tree) are at the heart of how most modern databases handle indexing. They quietly optimize our queries, reduce disk I/O, and keep performance consistent even as data grows. In this post, we’ll dive deep into how B-trees work, why they’re so effective, and how they became the backbone of fast data retrieval.
Understanding Indexing
Indexing creates a separate data structure that contains a subset of the table’s attributes, organized in a way that allows for much faster lookups based on those attributes. Think of it like the index in the back of a book – it allows you to quickly jump to the pages containing specific keywords without having to read the entire book.
What is a B-tree?
The B-tree is a self-balancing tree data structure designed to maintain sorted data and enable efficient searches, sequential access, insertions, and deletions, all in logarithmic time.
Unlike a simple binary search tree, where each node has at most two children, a B-tree is a multiway tree. This means each node can have a large number of children, a property known as a high fan-out. This high fan-out is crucial for minimizing the height of the tree, which directly translates to fewer disk I/O operations needed to find a particular record.
Anatomy of a B+ Tree Node
Let’s look at what makes up a typical B+ tree node:
Keys: Each internal node contains a set of keys, which are values from the indexed column(s), stored in ascending order. Child Pointers: Each internal node has pointers to its child nodes. If a node has n keys, it can have up to n+1 children. These pointers guide the search down the tree based on the value being searched for. Leaf nodes - the bottom-most level of the B-tree, contain the actual keys and, depending on the B-tree variant, may also contain the record pointers or the actual data itself. All leaf nodes in a balanced B-tree are at the same depth from the root, ensuring consistent search times. In a B+ tree, the leaf nodes are typically linked together in a sequential order, forming a sorted linked list. This linkage significantly optimizes sequential access and range scans. (B-trees do not have this linked list structure at the leaf level)
How B+ Tree Indexing Accelerates Queries
When you create an index on a column (or a set of columns), the database engine builds a B+ tree structure containing the values from those columns and pointers to the corresponding rows in the table.
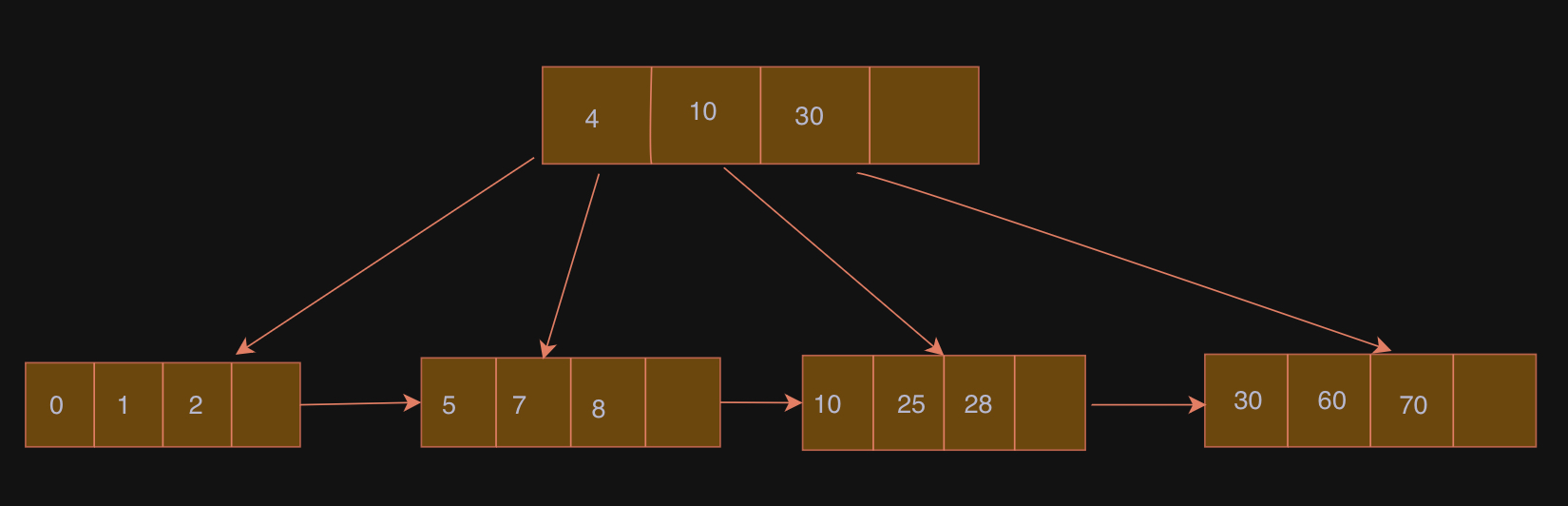
Example: Single Value Query
Consider our previous example: SELECT * FROM employees WHERE employee_id = 5. If there’s a B+ tree index on the employee_id column, the database performs the following steps:
- Start at the root node of the B+ tree.
- Traverse down the tree: Compare the value 5 with the keys in the current internal node to determine which child pointer to follow. The database would follow the node that stores values between 4 and 10 (second from left in our case).
- Reach the leaf node: This process continues until a leaf node containing the key 5 is found.
- Retrieve the record pointer: The leaf node associated with the key 5 contains a pointer to the actual row in the employees table where employee_id is 5.
- Fetch the data: The database uses this pointer to directly access and retrieve the requested row from the disk.
Instead of scanning the entire table (which could involve reading many disk blocks), the database only needs to traverse a few levels of the B+ tree and then directly fetch the target data block. This dramatic reduction in disk I/O is why indexing leads to significant performance improvements for search queries.
Example: Range Queries
Furthermore, for range queries like SELECT * FROM products WHERE price BETWEEN 25 AND 70, a B+ tree index on the price column allows the database to quickly find the first leaf node with a price of 25 and then efficiently traverse the linked leaf nodes to retrieve all products with prices up to 70, without having to examine the entire table.
Conclusion
So, the next time your database query returns in the blink of an eye, remember the elegant B-tree working diligently behind the scenes!