Understanding CQRS: Command Query Responsibility Segregation
Introduction
As applications grow in complexity, the need for scalable, high-performance architectures becomes paramount. One such architectural pattern that helps in handling complex business logic and performance bottlenecks is CQRS (Command Query Responsibility Segregation).
The Problem: Why Do We Need CQRS?
Meet Pizza Palace
Imagine you own Pizza Palace, the most famous online pizza ordering system in town. Everyone loves your extra-cheesy, double-pepperoni, pineapple-free pizzas. But suddenly, as more customers start placing orders, things begin to go wrong:
- Slow Orders Processing – Customers are waiting too long for their orders because the system is overloaded.
- Read & Write Clash – While one user is checking their order status, another is updating their delivery address, causing weird errors.
- Lost Orders? – Some customers claim their orders disappeared (maybe eaten by the system?).
- Scaling Nightmare – The system crashes when everyone orders pizza during a big game night!
Your traditional CRUD-based system isn’t cutting it anymore. Every order request (read & write) goes through the same model and the same database, creating a bottleneck.
Enter CQRS – A solution that separates read and write operations to keep the system fast, efficient, and stress-free.
How CQRS Works in Detail
The Two Models of CQRS
In CQRS, we separate the Command Model (Write Side) and the Query Model (Read Side):
-
Command Model (Write Side) – Handles all create, update, and delete operations.
- Ensures data integrity and applies business rules.
- Writes to the database.
- Sends out events for changes.
-
Query Model (Read Side) – Handles read operations.
- Provides optimized, pre-processed data.
- Often uses a separate database or storage optimized for fast reads.
- Listens to events from the write model and updates itself accordingly.
Two Ways to Implement CQRS
1. Same Model, One Data Store
- Both read and write models exist but share the same database.
- The read model gets optimized indexes and denormalized data.
- Easier to implement but still has some contention between reads and writes.
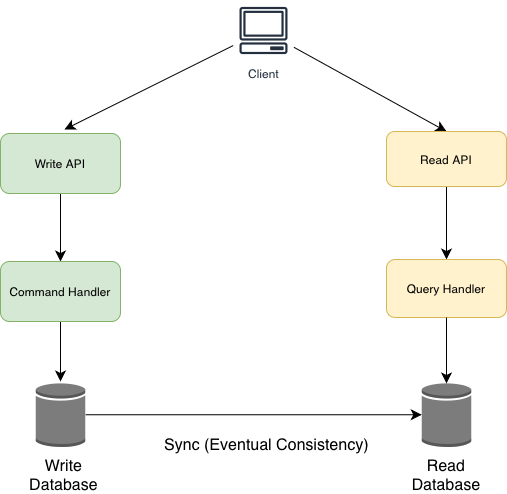
2. Separate Models, Two Data Stores
- Read and write models use different databases (e.g., SQL for writes, NoSQL for reads).
- Updates occur via event propagation from the write model to the read model.
- More scalable but requires synchronization logic and eventual consistency handling.
How Does the Sync Between Read and Write Work
When a change occurs in the Command Model (Write Side), it needs to be reflected in the Query Model (Read Side). Synchronization between the command and query sides is critical. A common approach is event-driven architecture, where the command side publishes events that the query side subscribes to, updating its data model accordingly. This is where Event handlers are used. The flow looks as follows.
- A Command is Executed: A user places an order for a pizza, triggering a Command (e.g.,
CreateOrderCommand). - Data is Updated in the Write Database: The order is saved in the write model’s database.
- Event is Generated: The system emits an OrderCreatedEvent to indicate a new order has been placed.
- Event Handler Listens to the Event: The event handler picks up the
OrderCreatedEvent. - Data is Updated in the Read Database: The event handler processes the event and updates the read model accordingly.
- Users Can Now Query Updated Data: The read model is now in sync with the write model, allowing fast retrieval of order status.
Event handling can be facilitated by message brokers like Apache Kafka or RabbitMQ, ensuring eventual consistency. Alternatively, without event sourcing, the query side might replicate data from the write side periodically or through database triggers, though this can introduce latency.
Advantages of Using CQRS
Performance Optimization – Since read and write operations are separated, each can be optimized independently.
Scalability – Read-heavy applications can scale the query model without impacting the write model.
Security – Enforces better security as different permission rules can be applied to read and write operations.
Flexibility – Different storage mechanisms can be used for reading and writing, such as NoSQL for reads and relational databases for writes.
Better Maintainability – Helps in managing complex business logic in large-scale applications.
Pitfalls of CQRS
Increased Complexity – Implementing CQRS requires additional infrastructure, data synchronization logic, and event handling.
Eventual Consistency Issues – In separate read and write models, data synchronization isn’t always instant, leading to potential delays.
More Storage Requirements – Having separate models often means duplicating data, which increases storage costs.
Requires Expertise – Debugging a CQRS system can be harder due to multiple moving parts like event buses, handlers, and separate data stores.
Overkill for Simple Applications – If your app isn’t complex or doesn’t have performance issues, CQRS adds unnecessary overhead.
When to Use CQRS
- You have highly complex business logic that requires separate handling for reads and writes.
- Your application is read-heavy - CQRS is particularly suitable for systems with high read-to-write ratios, such as e-commerce platforms or social media feeds, where read performance is critical
- You need scalability for different read and write workloads.
- You want event sourcing for better audit logs and traceability.
Avoid CQRS when:
- Your application is small and CRUD-based with simple logic.
- You do not have performance bottlenecks between read and write operations.
- You do not need event-driven architecture, as maintaining separate models can add unnecessary complexity.