
How Redis Works as a Cache in Distributed Systems
What is Redis?
Redis (REmote DIctionary Server) is a high-performance, in-memory data store widely used in distributed systems. Its speed, versatility, and ease of use make Redis a common choice in modern distributed systems, especially when building scalable, low-latency applications.
Why Use Redis as a Cache?
Redis is commonly used as a dedicated caching layer due to its in-memory nature and support for automatic expiration of data. Benefits include:
- Extremely low latency (microsecond-level read/write operations)
- Offloads repeated queries from the primary database
- Easily handles frequently accessed or transient data (e.g., user sessions, product pages)
- Built-in TTL (Time-To-Live) support for automatic cache expiration
How It Works
Basic Flow
- Read Path (Cache Aside Pattern):
- The application checks Redis for the data (the cache).
- If the data is found (cache hit), it is returned immediately.
- If not found (cache miss), the data is retrieved from the database and stored in Redis with an expiration time.
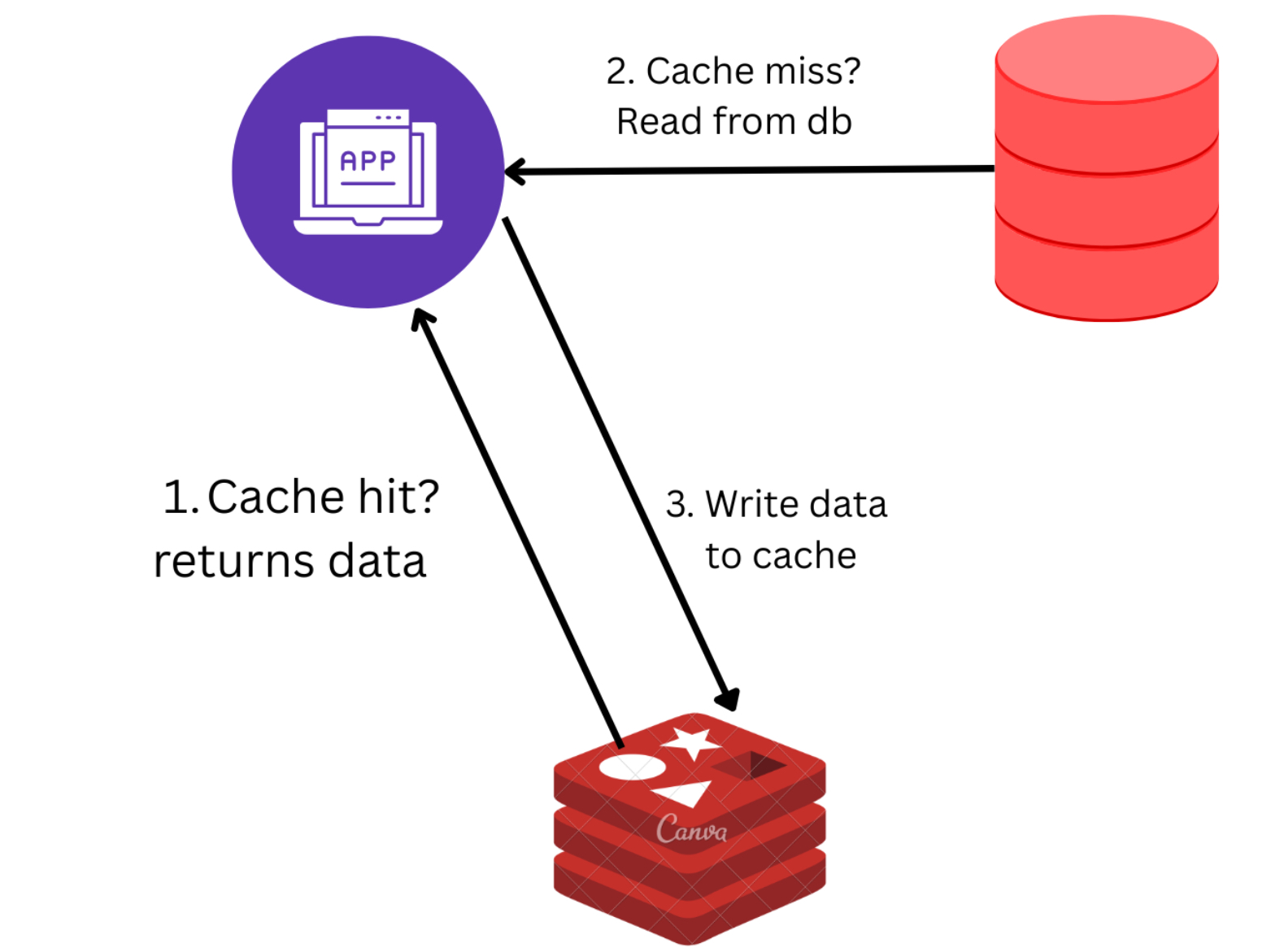
- Write Path:
- The application first updates the database.
- It then either deletes or updates the relevant Redis cache key to ensure consistency.
Caching Patterns
1. Cache Aside (Lazy Loading)
How it works:
In this pattern, the application checks Redis first for the required data.
- If the data is found (cache hit), it is returned immediately.
- If the data is not found (cache miss), the application fetches the data from the database and stores it in Redis for future use.
String cachedUser = redis.get(key);
if (cachedUser == null) {
String userFromDb = database.getUser(key);
redis.setex(key, 3600, userFromDb); // Store data in cache for 1 hour
}
return cachedUser;When to use:
- Cache Aside is ideal when the application can tolerate occasional cache misses.
- It is perfect for data that is expensive to compute or retrieve (e.g., database queries, API calls).
- Use it when the read load is much higher than write load, and when cache consistency is not a strict requirement.
2. Write Through
How it works:
Every write operation is first applied to the cache and then immediately written to the database.
- On reads, data is fetched directly from the cache.
void writeData(String key, String value) {
redis.set(key, value); // Write to cache
database.save(key, value); // Write to DB
}When to use:
- Write Through is useful when data consistency between the cache and the database is critical.
- It’s ideal when you want to ensure that every write goes into both the cache and database at the same time, reducing the risk of stale data.
- It is a good choice for scenarios where the data being cached changes frequently, and the overhead of dual writes is acceptable.
3. Read Through
How it works:
In the read-through pattern, the cache itself handles the reading from the database.
- If data is not found in the cache, Redis automatically fetches the data from the database, stores it in the cache, and then returns the result.
- The application only interacts with the cache.
String userFromCache = redis.get(key);
if (userFromCache == null) {
// Redis will internally fetch and store data from DB
userFromCache = redis.loadFromDB(key);
}
return userFromCache;When to use:
- Read Through is ideal when you want to abstract cache management from the application logic entirely.
- It’s perfect when the read volume is high, and you want Redis to handle cache population automatically.
- Use it when data is read frequently, but infrequently updated, and you want Redis to be the single source of truth.
4. Write Behind (Write Back)
How it works:
Writes are made directly to the cache, and the cache asynchronously updates the database after a delay or in batches.
- This reduces write latency and improves performance, but it introduces the risk of data loss if the cache fails before the data is written to the database.
// Write to cache
redis.set(key, value);
// Cache writes to DB asynchronously
redis.queueWriteToDB(key, value);When to use:
- Write Behind is suited for high-throughput applications where write latency is critical and eventual consistency is acceptable.
- Use this pattern when the application needs to handle large volumes of writes efficiently, such as logging systems or batch processing jobs.
- It’s also useful when you want to decouple the write process from the user request to avoid slow writes impacting user-facing performance.
Caching Challenges and Mitigations
1. Cache Invalidation
Problem: When the database is updated, the cache may still hold outdated values.
Mitigation: Use a proper invalidation strategy (e.g., delete or update the cache immediately after updating the database). Use pub/sub to notify cache nodes of changes.
2. Stale Reads
Problem: Data in the cache might become outdated, especially if the TTL is long or never set.
Mitigation: Set appropriate TTL values, implement version checks if needed, and refresh popular keys periodically.
3. Cache Stampede
Problem: When a popular key expires, many simultaneous requests may hit the backend.
Mitigation: Use locking (e.g., Redis SETNX) to let only one request repopulate the cache. Add jitter to TTLs. Consider early refresh or serving stale data while repopulating.
Key Takeaways
- Redis is a versatile tool in distributed systems, serving as a cache, key-value store, message broker, and persistent store.
- Caching with Redis helps reduce latency, offload database traffic, and improve overall application performance.
- There are multiple caching patterns (Cache Aside, Write Through, Read Through, and Write Behind), each suited for different use cases.
- Handling cache invalidation, stale reads, and cache stampedes is essential to maintain cache consistency and reliability.
- Redis can be configured for eventual consistency in some cases (e.g., Write Behind), depending on the requirements of your application.