
Apache ZooKeeper - Deep Dive
Hey there! Imagine you’re running a zoo… but instead of keeping animals in check, you have a bunch of wild, unpredictable distributed systems running around. Servers are trying to talk to each other, processes are fighting for leadership. Total chaos, right? Enter Apache ZooKeeper – the zookeeper of the distributed systems jungle! This handy tool keeps everything in sync, ensures no two servers fight for dominance, and helps your system run smoothly. In this blog, we’ll explore, where it’s used, how it works and how YOU can use it in system design. So, grab your safari hat, and let’s dive into the wild world of Apache ZooKeeper!
The Origin Story: From Hadoop’s Sidekick to Distributed Superstar
Apache ZooKeeper emerged from the Hadoop ecosystem in 2006. Picture this: engineers at Yahoo! were wrestling with HBase, a distributed database that needed a way to keep its nodes from stepping on each other’s toes. They needed a centralized service to manage configuration, naming, and synchronization. Thus, ZooKeeper was born, inspired by Google’s Chubby lock service but with an open-source twist.
In 2008, it graduated from a Hadoop subproject to a top-level Apache project, proving it could stand on its own four paws. Today, it’s a staple in systems like Kafka, HBase, and Solr.
Where is it Used?
ZooKeeper is the go-to buddy for any system that needs to coordinate multiple moving parts. Here’s where you’ll spot it in the wild:
- Configuration Management: Stores shared configs so every node in your cluster uses same config.
- Leader Election: Picks the “leader” node when your distributed pack needs a boss.
- Distributed Locks: Prevents nodes from fighting over resources like toddlers over the last cookie.
- Naming Service: Keeps track of who’s who in the distributed zoo.
- Queue Management: Helps systems like Kafka manage message queues without turning into a stampede.
Under the Hood:
Now, let’s pop the hood and see what makes ZooKeeper tick.
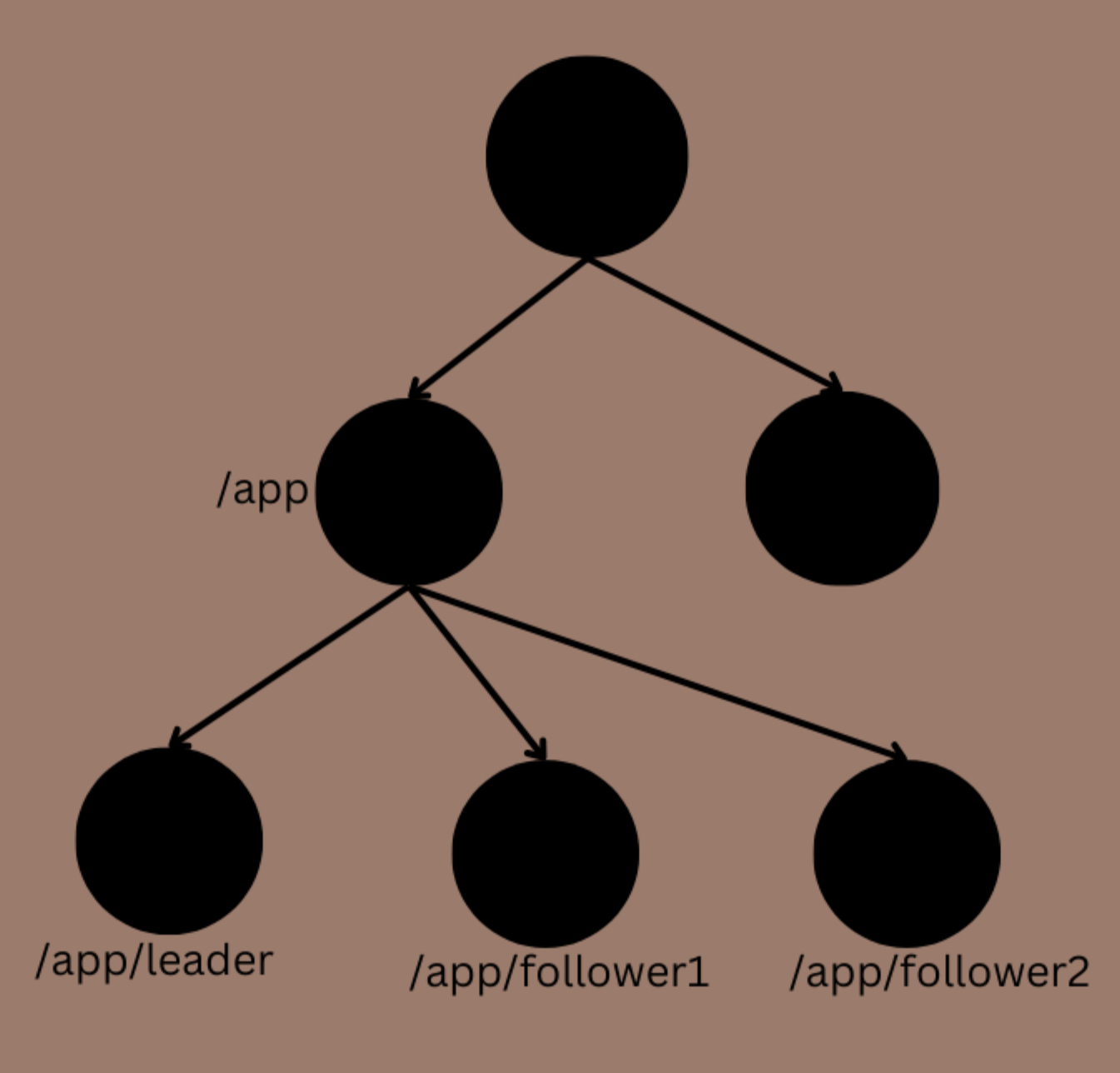
Znodes: The Building Blocks of the Zoo
At the heart of ZooKeeper is the znode, a hierarchical, file-system-like structure that holds data. Think of it as a tiny filing cabinet in a giant distributed office:
- Persistent Znodes: Stick around until you delete them—like that old mixtape you can’t let go of.
- Ephemeral Znodes: Vanish when their creator disconnects.
- Sequential Znodes: Get a unique number slapped on them, perfect for ordering tasks or naming nodes.
Znodes store small bits of data (up to 1MB), like configs or status flags. They’re organized in a tree, with paths like /app/leader or /locks/resource1. Simple, yet powerful!
Watches: The Nosy Neighbor
ZooKeeper’s watches are like having a nosy neighbor who texts you the second something changes. Clients can set a watch on a znode, and when it’s updated, deleted, or created, ZooKeeper pings them with a one-time notification. No polling!
Consensus Algorithm: ZAB, the Peacekeeper
ZooKeeper uses the ZAB (ZooKeeper Atomic Broadcast) protocol to keep its ensemble (a group of ZooKeeper servers) in sync.
- Leader Election: One server becomes the leader; the rest are followers.
- Proposal: The leader proposes updates (e.g., “Let’s change this znode!”).
- Voting: Followers vote “yay” or “nay.” If a majority agrees, the update is committed.
- Broadcast: The leader tells everyone, “It’s official!”
ZAB ensures strong consistency—every server sees the same data in the same order, even if a few crash mid-vote. It’s fault-tolerant as long as more than half the ensemble is alive (e.g., 3 out of 5 servers) - Let’s dive into this later!
Distributed Locks: The Bouncer at the Club
Need to stop nodes from trampling each other? Enter distributed locks:
- Create an ephemeral, sequential znode under a lock path (e.g.,
/locks/resource1/lock-). - Nodes check their znode’s number. The lowest number wins the lock.
- Others wait (using watches) until the winner’s znode disappears.
ZooKeeper’s atomic operations ensure no two nodes grab the lock at once.
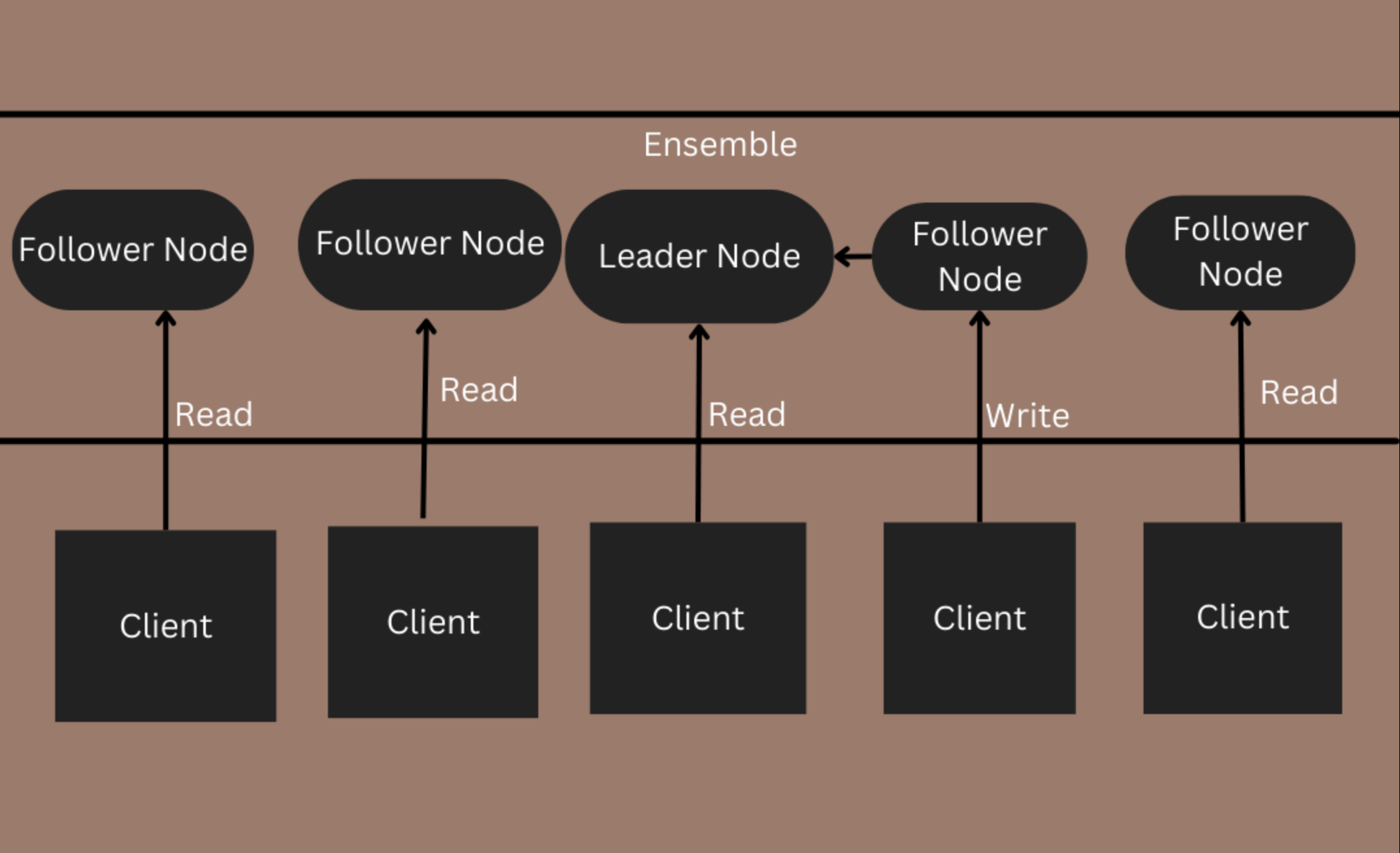
Reads and Writes: The Nitty-Gritty
-
Writes:
- Step 1: Client Request: A client updates
/app/config”, the request lands at any ZooKeeper server. - Step 2: Forwarding: If it’s a follower, it forwards the request to the leader like a loyal minion passing a note to the boss.
- Step 3: Proposal: The leader assigns a unique transaction ID (zxid) and proposes the update to the ensemble. Think of zxid as a timestamped sticky note saying, “This happened at 10:01!”
- Step 4: Consensus via ZAB: The leader sends the proposal to all followers. They log it to disk (to survive crashes) and vote “yes” if they’re happy. If a majority agrees, the leader commits the change locally and tells followers to do the same.
- Step 5: Acknowledgment: Once committed, the leader tells the client, “Done!” Followers sync up, ensuring everyone’s znode tree matches.
- Crash Survival: If the leader crashes mid-write, a new leader is elected. It checks the logs (persisted to disk) and replays any uncommitted transactions. If a follower crashes, it catches up by syncing with the leader’s state. As long as a majority survives, no data’s lost—strong consistency stays intact.
- Step 1: Client Request: A client updates
-
Reads:
- Step 1: Client Request: A client asks, “What’s in
/app/config?” Any server—leader or follower—can answer. - Step 2: Local Lookup: The server checks its in-memory znode tree and replies instantly. No consensus needed—reads are local and blazing fast.
- Consistency Guarantee: Because ZAB ensures all writes are committed in order across the ensemble, every server’s view should be identical at any given zxid.
- How They Get the Latest Data: When a client connects (or reconnects), it waves its last seen zxid and the server checks it:
- Client’s Behind (e.g., zxid 95, server’s at 101): The server’s ahead, so it serves the latest state The client updates its zxid to 101—boom, it’s current
- Client’s Ahead (e.g., zxid 100, server’s at 95): The follower’s lagging (maybe it missed a memo). It won’t reply until it syncs with the leader, fetching updates (96–100) via a diff or snapshot.
- Detecting Staleness: Each server tracks its own latest zxid and the epoch (a leader election counter). A follower knows it’s stale if its zxid or epoch lags the leader’s—say, epoch 1, zxid 95 vs. epoch 2, zxid 101. It syncs by replaying the leader’s log, catching up in milliseconds.
- How They Get the Latest Data: When a client connects (or reconnects), it waves its last seen zxid and the server checks it:
- Step 1: Client Request: A client asks, “What’s in
Pros and Cons:
Pros
- Reliability: Crashes? Network hiccups? ZooKeeper shrugs and keeps going.
- Simplicity: A clean API that’s easier to implement.
- Strong Consistency: No “maybe it’s updated” shenanigans.
- Scalability: Handles thousands of reads per second.
Cons
- Write Bottleneck: All writes funnel through the leader, so not suitable for heavy writes.
- Resource Hog: Needs dedicated servers and a decent chunk of RAM.
- Complexity: Setting up an ensemble isn’t an easy task.
System Design: When to Unleash ZooKeeper
Alright, let’s get to the part about when to whip out ZooKeeper in your system design. This section’s your cheat sheet—bookmark it, tattoo it, whatever works.
When to Use ZooKeeper
-
You Need Coordination Across Nodes:
- Example: A microservices app where one service must be the “leader” to process payments.
- Why: ZooKeeper’s leader election and locks keep things orderly.
-
Centralized Configuration:
- Example: A cluster of 50 servers needing the same database credentials.
- Why: Update one znode, and everyone’s in sync.
-
High Read, Low Write Workloads:
- Example: A status dashboard polling service health every second.
- Why: Reads scale across the ensemble; writes are rare enough to not bottleneck.
-
Fault Tolerance is Non-Negotiable:
- Example: A payment system that can’t afford to lose track of transactions.
- Why: ZooKeeper’s ensemble survives crashes like a super hero.
-
Distributed Locks for Resource Access:
- Example: A job scheduler ensuring only one worker processes a task.
- Why: Locks prevent duplicate work without breaking a sweat.
When NOT to Use ZooKeeper
- Heavy Write Loads: If you’re writing more than reading (e.g., a logging system), ZooKeeper’s leader bottleneck will make you cry. Try a database instead.
- Simple Apps: A single-node app doesn’t need ZooKeeper —it’s overkill.
- Data Storage: It’s not a database! That 1MB znode limit will haunt you.
Wrapping Up:
So next time you’re designing a system, ask yourself: “Do I need a zookeeper for this digital zoo?” If the answer’s yes, go forth and tame that distributed chaos—ZooKeeper’s got your back!